Writing a Go/C polyglot 🔗︎
Someone on a Slack I’m on recently raised the question of how you might write a source file that’s both valid C and Go, commenting that it wasn’t immediately obvious if this was even possible. I got nerdsniped, and succeeded in producing one, which you can find here.
I’ve been asked how I found that construction, so I thought it might be interesting to document the thought / discovery / exploration process that got me there.
Start from the beginning 🔗︎
We start with the problem statement: We need a source file that is both a valid C source file, and a Go source file. We’ll keep open the Go language specification, and N1570, the final draft C11 spec doc (the final published version, ISO/IEC 9899:2011, is behind an ISO paywall) and use those to dig for an opening.
I know (or believe) based on writing Go before that Go programs need to start with a package declaration. That’s pretty constraining if true, so let’s check the spec to verify that. Per the spec, we have
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
PackageClause = "package" PackageName .
PackageName = identifier .
So, we confirm that the first tokens in a Go source file must be the literal word package followed by an identifier.
I can’t imagine a way to make a valid C source file starting that way (although please let me know if I’m wrong!), so whatever cleverness we do has to happen before this point. The only way I can think of to inject source text that doesn’t appear in the token stream is by writing comments, so this observation implies to me that we’re going to be playing games with comment syntax. A common trick in polyglots is to find a way to end up with one half of the program as a comment to each language, so this feels like a productive avenue to explore.
A comment, if I may 🔗︎
Go and C have very similar comment syntax — // for line comments, /* … */ for block comments. So if we start a file with either // or /*, both language will process it as a comment. If we can find some subtle way to make one language stop think the comment has ended, but not the other, we’ll be well on our way to victory. So, we turn to the specs to look for subtle distinctions in behavior:
On comments, the Go spec says:
- Line comments start with the character sequence
//and stop at the end of the line.- General comments start with the character sequence
/*and stop with the first subsequent character sequence*/.
And C says:

At a glance, these sound effectively identical. Neither language allows nesting /*, and // continues “the end of the line” or “the next new-line character,” which sound the same in any circumstance I can imagine. I briefly considered investigating if the languages perhaps differed on the definition of “new-line character” (\r, anyone?) but decided to shelve that for now in favor of looking at other transformations that might happen even before comment processing. If we can cause the lexers to see different character streams, we might be able to win. That lead me to … trigraphs!
Tri-whats? 🔗︎
The C programming language was designed (I believe — Unix buffs please @ me) for a 7-bit ASCII character set, and made use of most of the punctuation characters available in ASCII. However, it’s since been ported to systems that don’t use ASCII, most notably including IBM mainframes and others operating in EBCDIC. EBCDIC lacks several important punctuation marks used in C, such as the {} curly braces, so C provides a mechanism to represent these in such encodings. Certain three-character sequences, known as trigraphs, are replaced very early in source processing by a single punctuation character. This lets us create a character stream where C sees an end-of-comment delimiter and Go doesn’t, or vice versa, since C will process the trigraphs and Go will not. Once more, we go to the spec:

I was hoping, in particular, to find a trigraph that generated a / or a *; this would make it trivial to generate a sequence that C interpreted as */, but which Go ignored. Unfortunately, lacking for one, I can’t quite see a way to make any of these useful to us. The ??/ trigraph will let us “hide” a / character from the C compiler, but using that to start a comment will require that Go see the ?? sequence, and we can’t use it to end a comment, since we can’t directly precede the / by both ?? and *.
The humble backslash 🔗︎
Glancing back at the C spec on comments, though, we find an interesting example in the non-normative examples section:
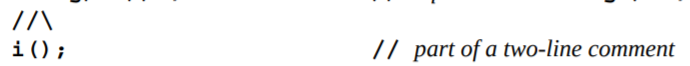
It appears — I may have once known this, but had forgotten it — that you can extend a // comment onto a second line, in C, by ending the line with a backslash character. Digging more, we find an explanation in §5.1.1.2p2:

You might be familiar with the use of a \ to spread C macro definitions across multiple lines; it turns out this is a more-general feature of the C source processing, which lets us splice multiple physical lines anywhere in a program, including inside comments. Go, on the other hand, lacks for this feature, giving us the critical primitive we need:
// this is a comment in both languages \
This line is a comment only in C
In general, one such primitive often suffices to build a polyglot. We extend it for convenience like so:
//\
/*
This code is recognized by the C compiler, but ignored by Go.
We can then write our C program in that space, where the Go compiler will happily ignore it. Furthermore, we can break out of that mixed mode at any time by the simple expedient of a // */ — the // hides it from C, and the */ ends the block comment for Go.
Before doing so, though, we want to tell C to ignore what comes next, so we can switch to writing Go; We do that with the simple expedient of a #if 0, causing C to start ignoring everything that comes next:
//\
/*
C code goes here
#if 0
//*/
Go code goes here
All that remains is to finish. If we leave off a #endif, the C preprocessor will complain, but a bare #endif isn’t legal in Go. One more iteration of our first trick, in which we codeswitch into “C-only” mode, suffices:
//\
/*
(C code goes here)
#if 0
//*/
(Go code goes here)
//\
/*
#endif
//*/
And we’re done, and can write any code we want in both Go and C, with each compiler only “seeing” their respective section.
Conclusion 🔗︎
The ultimate “trick” here is pretty straightforward; Once you point out the //\ bit of trivia, I expect most programmers could find the rest of the construction, or a similar one, fairly quickly. However, I hope by writing up my train of thought and logic that lead me to stumble on this trick, I can demystify how I got here, and maybe teach something useful about the kinds of reasoning or research that helps one arrive at oddities like this. In my experience, the techniques I used here of reasoning around constrained problems, referencing specs to learn “ground truth” about a system, and exploring interactively end up being useful in far more circumstances than just toy one-off hacks.
