In 2017 and 2018, I (along with Paul Tarjan and Dmitry Petrashko) was a founding member of the Sorbet project at Stripe to build a gradual static typechecking system for Ruby, with the aim of enhancing productivity on Stripe’s millions of lines of Ruby, and eventually producing a useful open-source tool. I’m very proud of the work we did (and that others continue to do!) on Sorbet; I think we were very successful, and it was one of the best teams I’ve worked on in a number of ways.
I think a lot went well in the project, in all of our architecture implementation, and overall project strategy. This is the first of what I hope will be a series of blog posts exploring some pieces of the design and development of Sorbet, and some lessons that I think may generalize to other projects. I don’t claim that these techniques are necessarily novel, just that they worked for us and I hope we make a useful case study for others.
Testing in Sorbet 🔗︎
From the first day of the project, we knew we wanted to invest heavily in tests and testing infrastructure. All three of us had strong beliefs from our respective careers that this investment from the start would greatly improve both our development velocity and the quality of the tool we would produce. The very first commit in the project history consists of a simple “Hello, World” unit test along with the infrastructure to build and run it.
We also knew that we ultimately wanted the bulk of Sorbet’s test suite to consist of a corpus of .rb files, each annotated in some way with the errors the typechecker was expected to produce 1. However, as we initially built out the pipeline, we also wanted to be able to test individual passes as we built them, before we had error-reporting infrastructure! We also expected these tests to be useful to aid debugging and isolating issues as we developed.
Record/replay testing 🔗︎
The strategy we settled on was an instance of what I refer to as “record/replay” testing. Instead of hand-writing unit tests that invoked the code under test and made assertions about the result, we built a framework that automatically compared the output of the tool to the output from an earlier version. This framework allowed us to record the output of running the typechecker until a given phase on a set of manually-provided example programs and printing the current internal representation. We would then check in this output to the source tree in git, and the tests would replay these examples. The test suite would execute the branch under test on the same inputs until the same point in the pipeline, and verify that the resulting output was identical to the saved one.
In order to enable this process, as we built each intermediate representation of the typechecker, we also built a pretty-printed output format for that representation. And as we implemented passes that transformed these representations, we also added command-line options for dumping the current representation after any specified pass. These features (which are shared in some form by most compilers) were also valuable for manual debugging, which meant that building our test infrastructure on top of them was a bit of a two-for-one.
Example: Desugaring boolean operations
By way of example, we can look at a test still present in the codebase. Sorbet (as is common for compilers) internally translates a || b into something like if a then a else b end early in its pipeline. These expressions have identical semantics, and this transformation (or “desugaring”) means that later pieces of the pipeline don’t need to understand the “||” operator at all.
This transformation is tested via this test file, which contains instances of the || and && operators, and this expectation file, showing the desugared AST. By way of naming convention, .desugar-tree.exp suffix on the expectation file instructs the test suite to run Sorbet over the input ops.rb file until the “desugar” pass, and then pretty-print the resulting tree, and compare it against the saved .desugar-tree.exp file.
Maintaining .exp files 🔗︎
Importantly, all the .exp files can be automatically regenerated. The tools/scripts/update_exp_files.sh script in the sorbet repository discovers all .exp files in the repository, and re-generates them from the corresponding .rb file using the current code. We also used this tool to create a new tests: an engineer would write an .rb file, create an empty .exp file for the pass(es) they wanted to test, and run the update script to populate the initial recording.
Updates to .exp files were common, especially early in the development process. We were evolving all pieces of the system, including the our internal representations, the transformation passes operating on and between them, and the type system. Changes that altered a transformation would update a few expectations, and global changes to the IR might update essentially every .exp file containing examples of that IR.
We adopted a convention that when submitting a pull request, all updates to existing .exp files were separated into their own commit. This allowed reviewers to review the code changes in the other commits, and then separately observe their effect on the resulting IR by looking at the final update commit. You can see an example in our history, updating files for the effect of fixing a bug.
Humans in the loop 🔗︎
One property I find fascinating about this testing style is that, as you think about it, it gets a bit tricky to describe exactly what you’re testing. The tests check for an exact match of the output, but especially while we’re developing the tool, this output is expected to change regularly as we build out and refine all our transformations. And in response, we’ve made it super easy to brute-force update the tests by re-running the update script. It’s easy to imagine such a scheme barely testing anything at all: whenever a test fails, just run the script, and voilà, passing tests!
I think the tests make a lot of sense, though, in light of an observation I made in my previous post: The point of the tests wasn’t to ensure correctness by themselves; they were instead explicitly thought of as a tool to help the engineers who were developing this project work more quickly and with more confidence. As tools to this end, they served us very well, and worked better than most other schemes we might think of, for a number of reasons:
The expectation updates are reviewed 🔗︎
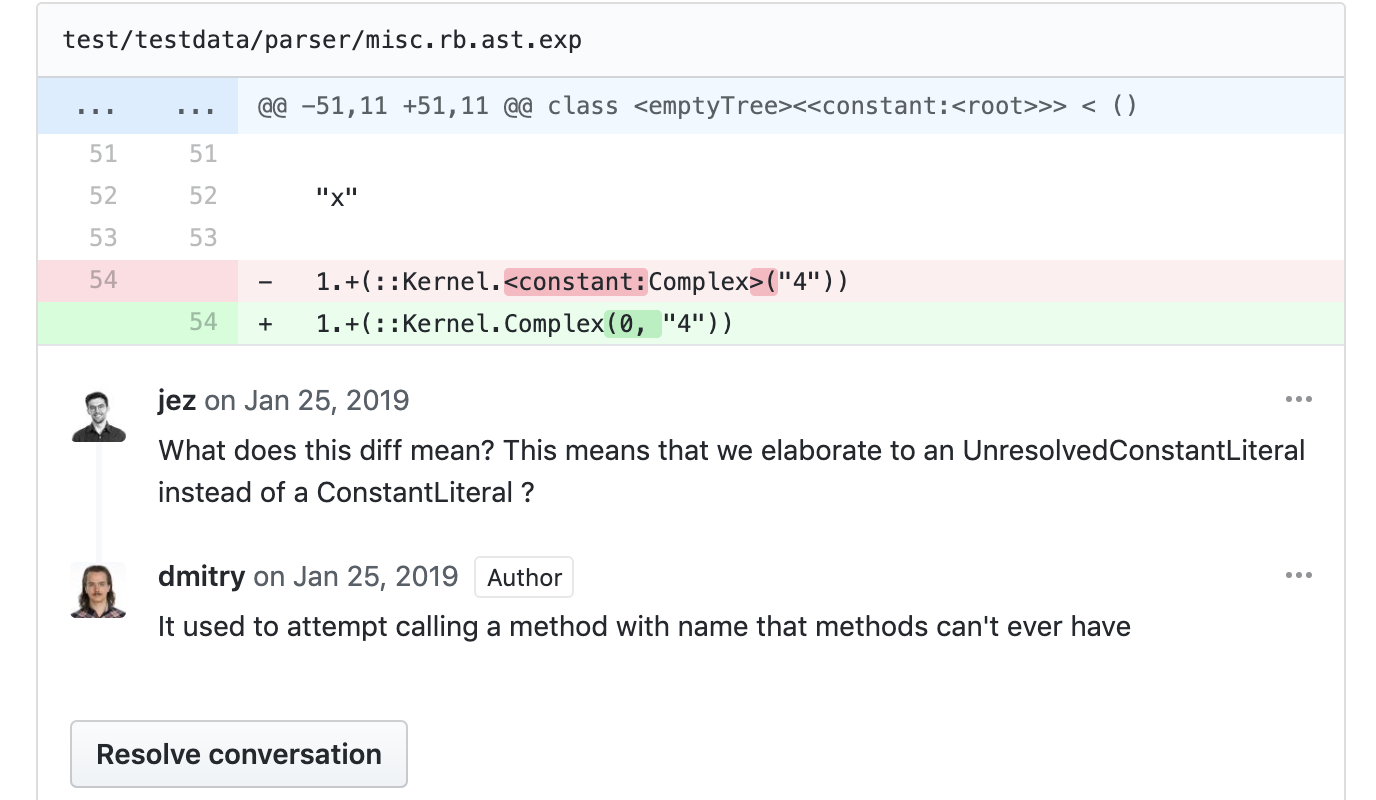
The updates to the .exp file, by convention and agreement among the team, were reviewed both by the author of a pull request and by their reviewer. This step was crucial and let us check for properties such as:
- Changes only impacted the files we expected. For example, if a change to one pass of the typechecker altered the output for earlier passes, or a change to one language feature impacted output for tests that didn’t use that feature, that was a smell we might have an accidentally regression.
- Individual changes were expected. Since the
.expfiles were designed to be human-readable, and were stored alongside code, github would render fairly readable diffs, and we would actually read them and compare the impact to our understanding of the expected behavior of the code being changed.
The updates (and especially new examples introduced in a change) also served as machine-checked examples for the reviewer of the change. By providing a test case exercising the change, the author provides a concrete example of what the change is meant to accomplish, which our infrastructure guarantees is kept up-to-date.
Expectations files are easily updated 🔗︎
A common complaint I from developers when talking about tests is about “brittle” tests, which break virtually every time you make a change, even if the change didn’t impact the actual feature. Sorbet’s “exact match” tests were in some ways extremely brittle, since by design most changes would “break” a test. However, because updating the tests was completely mechanical, they were in practice much less brittle than a hand-written set of assertions would be, because updating them required a minimum of time and effort. In an evolving and informally-specified system like Sorbet in its early days, any kind of tests would likely be subject to brittleness as core assumptions changed. Optimizing for the ease of fixing the tests, instead of trying to make them more robust, was a worthwhile tradeoff.
Adding new tests was very easy 🔗︎
Adding a new test consisted solely of writing a Ruby source file which demonstrated the feature or patterns you wanted to test, touching one or more empty .exp files, and running the update script. As we built out the file error-checking approach I explained earlier, we ultimately even removed the need to create a separate .exp file. Making tests easy to add and easy to update encouraged us to add tests for every single feature we wrote.
We also later added a fuzzer to stress-test the pipeline, and could easily drop any crashing test cases it found into our corpus as additional regression tests.
As sorbet matured, we grew stronger correctness checks 🔗︎
In the early days of the project, Sorbet was not deployed anywhere and had no users, and so the cost of regressions was fairly low: they cost us time in catching, debugging, and fixing them, but had no impact outside of our team. As such, it was acceptable to occasionally suffer a regression because someone failed to notice an change in a .exp file, so long the system accelerated development overall. And once we did notice a regression, using git log on the expectation files could often identify the responsible commit even without requiring a git bisect.
As we matured towards deployment inside and eventually outside of Stripe, we grew additional tests that tested the system more for end-to-end correctness, to further limit regressions for our users. These tests looked like an increasing number of the # error: tests that I described above, as well as a CI job that ran every sorbet PR against Stripe’s entire Ruby application. These tests gave us greater confidence that we weren’t breaking the user-facing behavior, and as we matured we moved towards using them as our preferred mode of testing, while retaining a handful of expectation tests to test particularly important or subtle details of the internals.
Beyond Compilers 🔗︎
One of my favorite aspects of working on compilers and typecheckers is that, at a macro level, you can think of them as giant pure functions of type String → String: They accept one or more source files, and emit zero or more output files along with a set of errors or warnings, and typically persist no internal state. This property makes them comparatively easy to test, and otherwise makes them more straightforward to reason than lot of other software I’ve worked on.
That said, I think these techniques and some of the ideas here can be helpful even for systems with messier or more complex interfaces. Record/replay tests can be a cheap way to get confidence that a change does not impact some subset of behavior, and, so long as they’re easily re-recorded, at worst cost only a little time on changes that do impact behavior.
Here’s a few thoughts on how I’ve adopted similar techniques in other systems. Many of the suggestions here apply beyond the record/replay pattern, but I’ve presented them from that perspective in particular.
Network services 🔗︎
Network services can be as nice for testing as compilers, because they have a very well-defined interface: the HTTP or RPC network boundary. Instead of recording input and output text files, you can record incoming requests and the expected response (perhaps as raw HTTP wire protocol, or as some pretty-printed form easier for humans to manipulate).
For services without (substantial) internal state or external dependencies, this technique is often just as powerful and convenient as it is for local programs.
Managing state 🔗︎
When a system has internal state, it’s not sufficient just to capture input/output for a single request in order to test it. You somehow need to test the interactions of requests with the internal state. For handling state in a record/replay test, I know of two main strategies for generalizing recording, which can often be combined in part:
- You can lift the state into the recordings. Perhaps you can record a series of API calls which create any necessary state to demonstrate the paths you want to test. Or you can define a miniformat that directly deserializes into the internal state to define the initial conditions.
- You can make available a rich set of “default” state for each test to run on (a la fixture data), containing, for instance, a few users with well-known usernames and other objects. Traces can then operate on these objects by stable ID, and exercise interactions with them.
External dependencies 🔗︎
If a service has external dependencies — perhaps it calls out to another microservice, or an external provider — you will need to be able to control those interactions to some extent in order to successfully record and replay traces. Here, again, I consider two strategies, which are somewhat parallel to those for handling state:
- Record the interactions. The recorded trace can also include pre-recorded responses from any services that the service under test talks to, and the test framework can inject those responses as necessary. This approach is flexible, but also risks being brittle to changes in the pattern of interaction with external services. Without access to a real version of the dependencies, you may not be able to regenerate the traces automatically, requiring tedious manual updates to tests.
- Write fakes for dependencies. A “fake,” as I use the term, is a standalone implementation of a dependency’s API that behaves in a predictable way, which can be injected for the purposes of testing. Fakes allow executing traces without brittle recordings of the interactions with the fakes, and can allow tests to be much clearer and less brittle. However, faking a complex dependency may involve writing a substantial amount of code.
Nondeterminism 🔗︎
Record/replay tests generally require a deterministic system; if identical input yields different output in subsequent runs for any reason, an exact comparison will fail. In general, I’ve found that making systems (at least optionally) deterministic is extremely helpful for testing and debugging a system in general, and so my first approach to testing such systems is to see how feasible it is to make them deterministic, using techniques such as:
- Adding an option to assume a fixed timestamp. Sometimes you can do this at a language or OS level (e.g using Timecop for Ruby), or else you can refactor the code under test to support passing in a timestamp.
- Using a deterministic PRNG with a controllable seed, at least during testing. Even replacing the RNG entirely with “return 4” can sometimes work for simple cases!
- Explicitly sorting lists in appropriate places. If a program reads a list of files in filesystem order, runs N threads and accumulates results as the tasks finish, or iterates over an unordered hash table, this can inject a source of non-determinism without any explicit randomness. Adding
sortcalls at appropriate moments will restore predictable behavior. Sorbet has all of these challenges, and so we make sure to sort various lists for determinism.
Sometimes you can also modify your output format to elide irrelevant details that are too brittle. For instance, in Ruby, many objects print as something like #<Object:0x00005c62fdd14978>, where that hexadecimal string is a pointer address. In other projects at Stripe, we would often write post-processors for traces that replace the address with all-0’s so that output from different runs of the same program would be comparable. Sorbet eventually grew a command-line option to remove some information from output during snapshot testing for this reason.
If the nondeterminism is too hard to patch for any reason, one other path forward is to add some kind of pattern-matching to your “expected output” files. Perhaps you can support writing a regex to match strings, instead of exact comparison. Going down this route can be powerful and even make tests easier to read (by eliding irrelevant details), but also adds complexity and complicates regenerating tests when necessarily. Use your judgment!
Conclusion 🔗︎
I think our testing strategies were one of many reasons that the Sorbet project was successful. We are far from the first to employ these ideas, but I hope this writeup of how we approached testing might be helpful or interesting to others, as well as exploring some more of how I think about testing.
As a final note, especially if you’re considering adopting record/replay testing in a new project, I want to emphasize that (for me, at least!) the point of tests and test suites is to make development on a project faster, safer, and more productive overall. If these ideas or techniques aren’t working for you, I encourage you to try a different approach or even delete some tests entirely. If you do build something based on any of these ideas and find it helpful, please drop me a line and let me know!
-
You can see an example of such a test in the current codebase. Lines with
# error:comments indicate expected errors; If typechecking a test file produces additional errors, or fails to produce any of the annotated errors, the test will fail. Use ofT.reveal_typeandT.assert_type!make this style very expressive. ↩︎
